There are 10K concurrent users on an online store, and they all try to buy the last sneaker in stock at the exact same time. How do you make sure that only one person gets it?
If you know what mutexes are, feel free to skip this section. Say you have 10K threads running the following function:
int counter = 0;
void *func(void *arg){
counter += 1;
}
The expected value of counter is 10K, but this is not guaranteed.
counter += 1
does three things: reads the value of counter, adds 1 to it, and sets
counter to it. If two threads read the same value of counter before
incrementing it, it will effectively only increase by 1. We can use locks
to guarantee that every thread increments counter exactly once:
int counter = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
void *func(void *arg){
pthread_mutex_lock(&mutex);
counter += 1;
pthread_mutex_unlock(&mutex);
}
The code between the pthread_mutex_lock/unlock() is called
the critical section, which only one thread that "acquires the lock" is
allowed to execute at a time.
A distributed lock is like a mutex, but it synchronizes access to resources in a network rather than within a machine. When there are several clients requesting to access a resource, locking can enforce that only one of them gets it.
*usually there's middleware between the client and other services, but I omitted it for simplicity
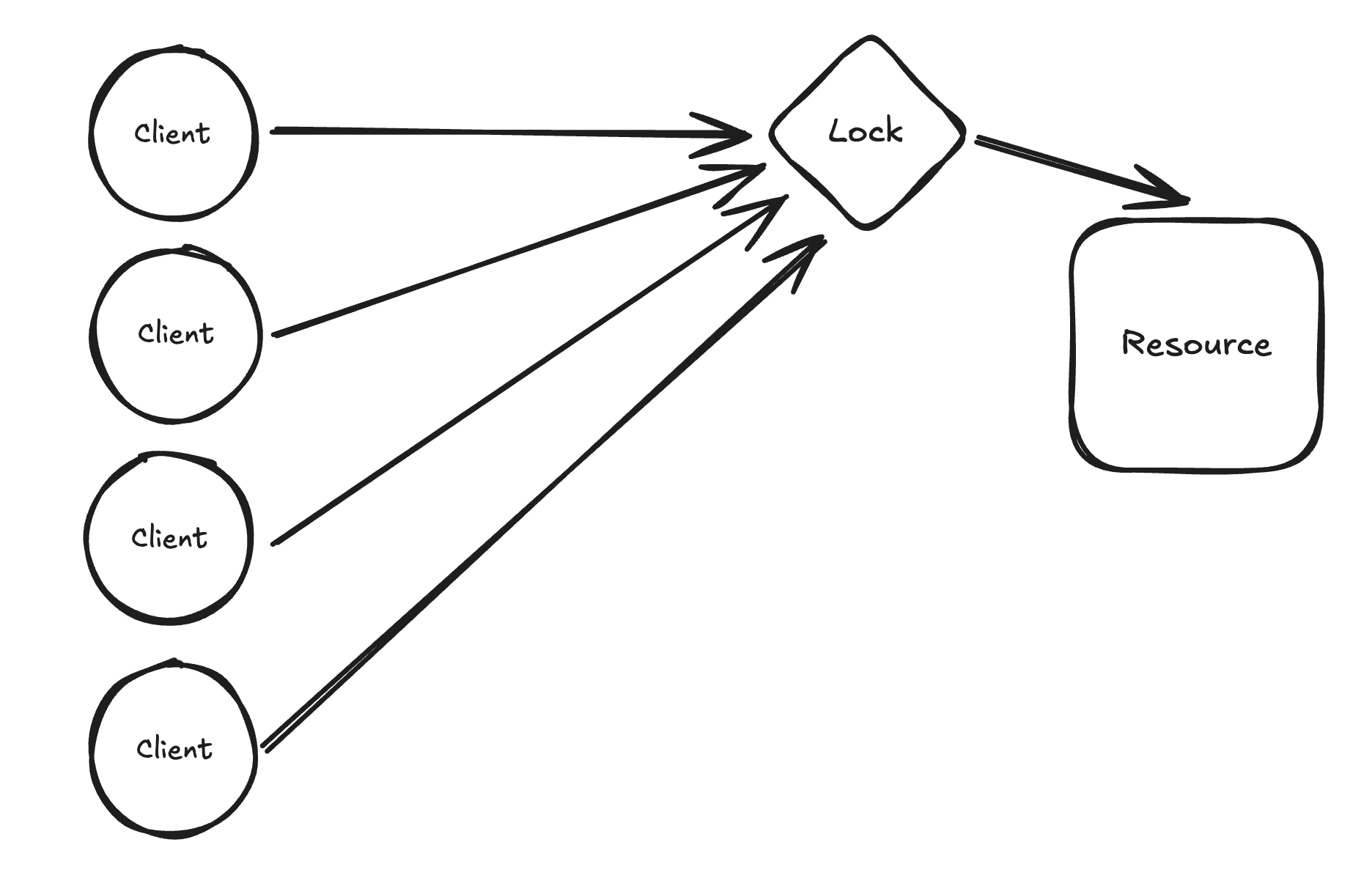
We can use Redis to achieve a naive (but decent) implementation. To make it clear, I will use the example of booking rides on an app (Uber). A driver can only ride with one person at a time, so we must "lock" a driver when the client books a ride with them.
To lock a driver, we could use the following command:
SET <driver_id> <client_id> NX
In plain english, this command tells Redis to set the (driver_id, client_id) key-value pair only if the key does not already exist (hence the NX flag). If this command fails to set the key, it indicates that the driver is locked by some other client.
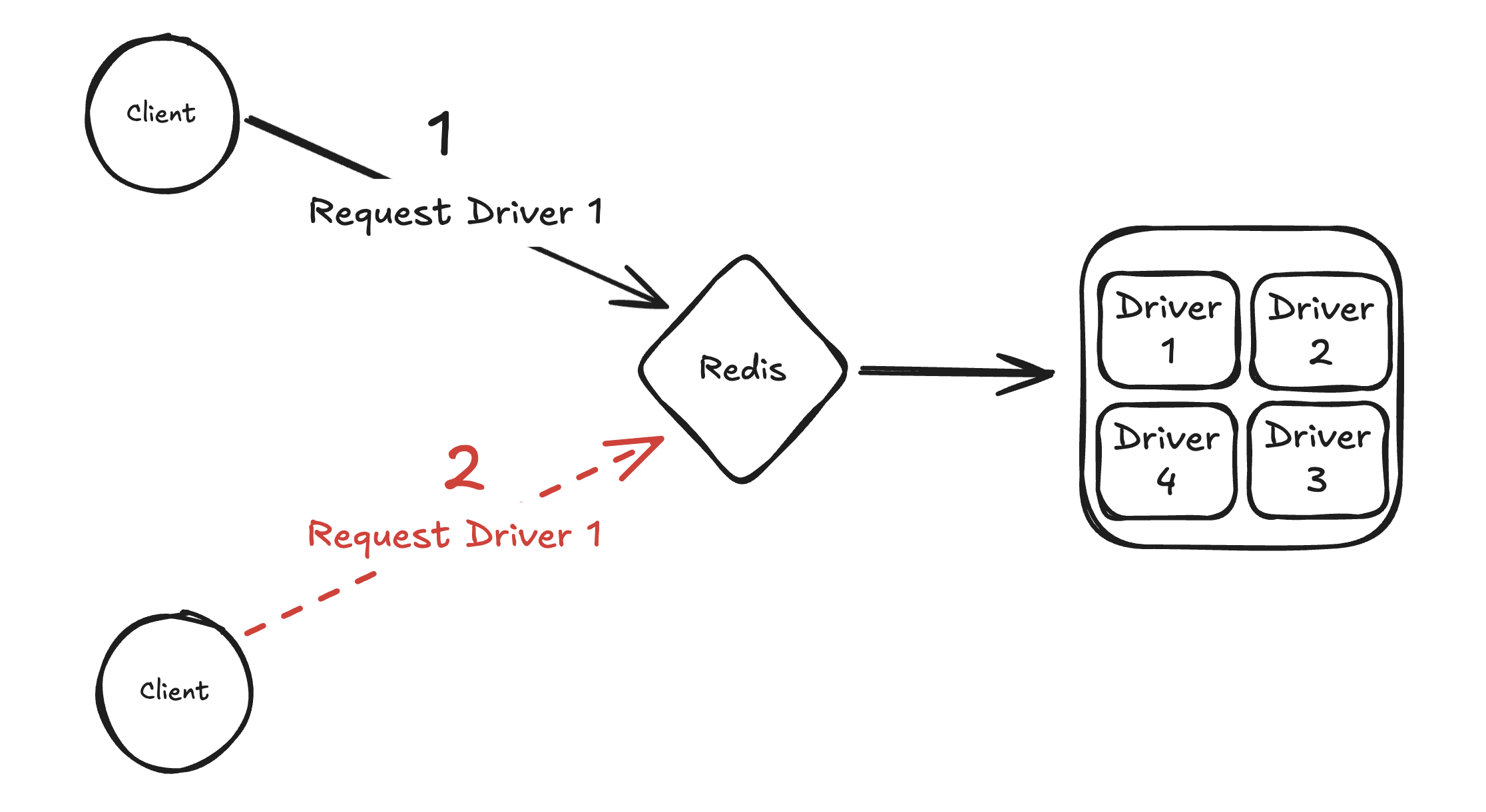
The client can delete the <driver_id> key from Redis
once their ride is done.
Also if you are wondering, all single commands in Redis are atomic. For us, this means that it will execute the SET instructions one at a time.
This implementation is quite error-prone even disregarding security issues, etc. A big problem with this approach is that the whole app stops working when this redis instance fails. This is called a single point of failure.
This algorithm uses an odd number of independent Redis instances (no replication) to avoid a single point of failure. Here is my simplified summary of the algorithm:
To lock a driver, a client can sequentially send a
SET client_id driver_id NX command to each Redis node and
keep a tally of how many of these execute successfully.
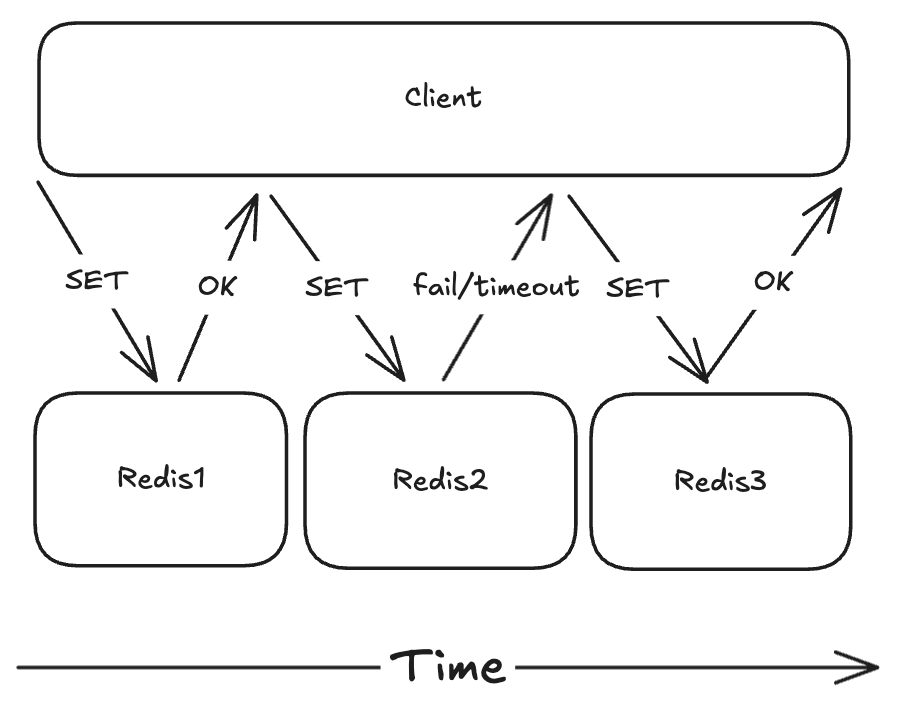
If a majority of the nodes successfully execute the command, then the client has aquired the lock for that resource. After the client has finished, it has to release the resource by deleting the driver_id in all redis nodes.
To prevent live/deadlocks and buggy clients from hogging locks, we can add a few more steps to the algorithm.
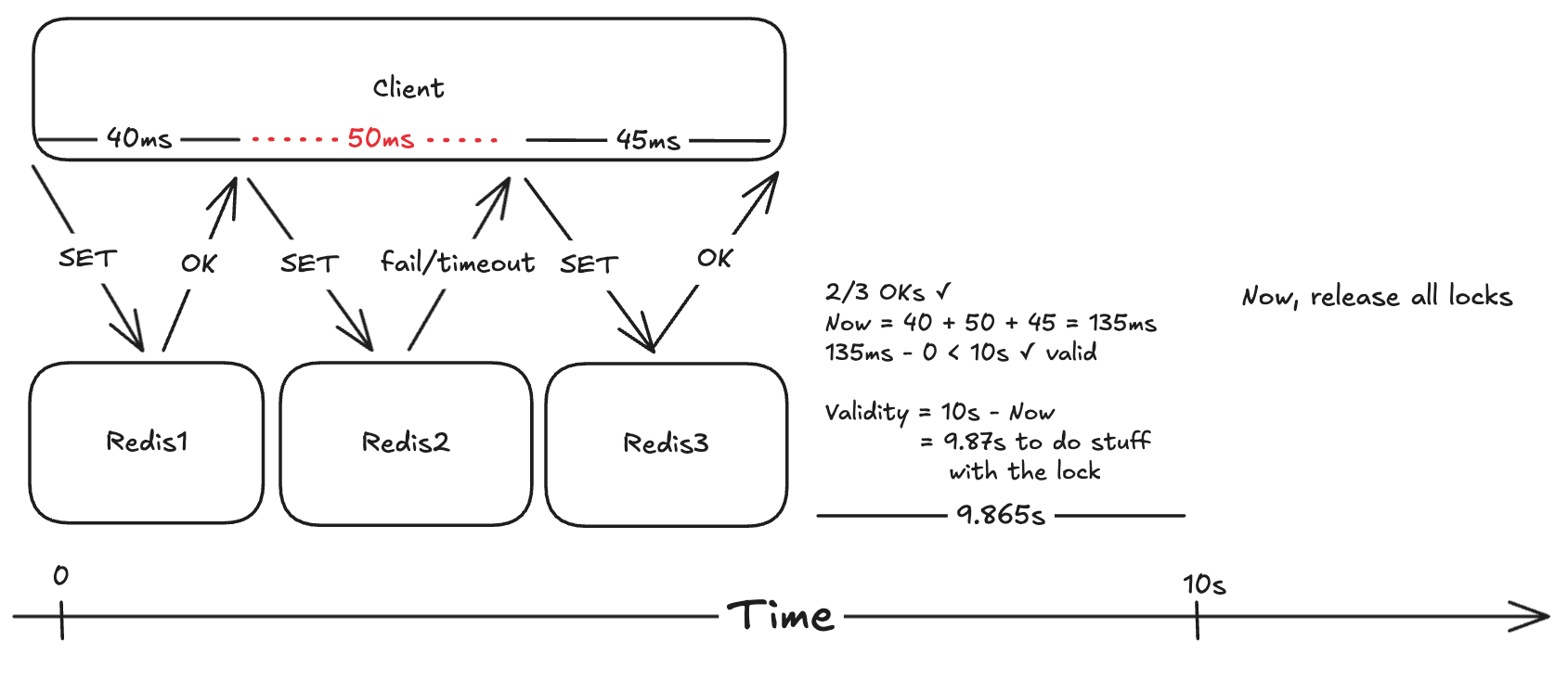
The client now has some time to use the resource before the lock expires called the validity time. This can be calculated by subtracting elapsed time from the initial validity time (10s from the first request is sent to the Redis node).
This solves the single point of failure problem. If we have 5 nodes, up to 2 of them can fail and our app will still work.